VoxMovies is an audio dataset, containing utterances sourced from movies with varying emotion, accents and background noise.
To bechmark performance of speaker recognition systems on this entirely new domain, VoxMovies contains a number of domain adaptation evaluation sets.
856
SpeakersVoxMovies contains speech from speakers in VoxCeleb1 and VoxCeleb2 (speaker recognition training datasets), allowing for domain change within the same identity to be investigated.
1,452
MoviesVoxMovies is sourced from key moments in a wide variety of movies from the Condensed Movies dataset. These movies cover many different genres such as comedy, action, romance and horror.
8,905
UtterancesVoxMovies consists of audio clips. On average each identity has utterances from 2.7 different movies. Variation in emotion and background noise is therefore seen within each identity, as well as across identities.

Movie genres featured in VoxMovies
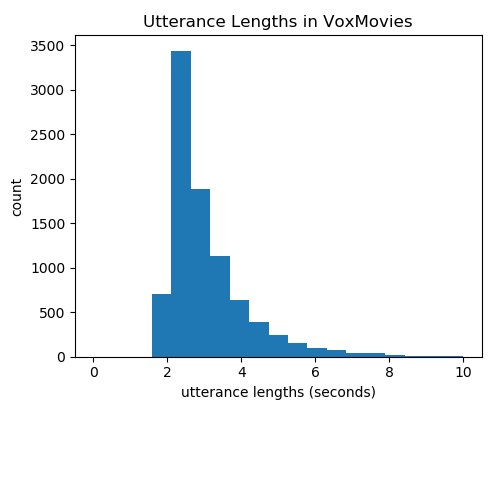
Utterance lengths